
Achieve a 4x speed-up in just 3 lines of code! Python is an excellent programming language for data processing and automating repetitive tasks. Whether you are working with large web server logs or millions of images to resize, Python has libraries that simplify these tasks.
However, Python is not always the fastest option. Typically, Python runs as a single process on a single CPU core, which means if your computer has multiple cores, a significant portion of its processing capacity may be wasted.
Leveraging Parallel Processing
To maximize your computer’s processing power, you can run Python functions in parallel using the concurrent.futures module. This allows your program to utilize multiple CPU cores effectively, significantly accelerating data processing tasks.
The Standard Approach
Imagine you have a directory filled with photos and you want to create thumbnails for each one. A simple Python script using glob and the Pillow library could do that as follows:
- Gather a list of files to process.
- Write a function to handle each file.
- Use a loop to process each file sequentially.
Running this script on a folder with 1,000 JPEG images might take around 8.9 seconds if using a single CPU.
Splitting the Workload with Process Pools
Instead of using just one process, you can optimize this by taking advantage of multiple cores:
- Split the list of JPEG files into smaller chunks.
- Run individual Python processes for each chunk.
- Combine the results after processing.
This approach can lead to 4 times more work done simultaneously.
Here’s how you can do it:
- Import the
concurrent.futureslibrary:
import concurrent.futures- Create a Process Pool to manage multiple instances:
with concurrent.futures.ProcessPoolExecutor() as executor:- Use
executor.map()to execute your function in parallel:
for image_file, thumbnail_file in zip(image_files, executor.map(make_image_thumbnail, image_files)):This modification may lead you to process the same 1,000 images in just 2.2 seconds, demonstrating a 4x speed-up.
When to Use Process Pools
Using Process Pools is highly beneficial when:
- Tasks can be executed independently.
- You are processing large datasets like web logs or images.
However, they may not be suitable if:
- Data transfer between processes is inefficient.
- You require sequential processing based on previous results.
Understanding the Global Interpreter Lock (GIL)
Python’s GIL allows only one thread to execute at a time; hence, multi-threading does not provide true parallelism. In contrast, Process Pools enable multiple instances, each with its own GIL, allowing actual parallel execution.
Conclusion
Thanks to the concurrent.futures module in Python, you can leverage all CPU cores to enhance your script’s performance significantly. Don’t hesitate to try it out—once you understand it, it becomes as straightforward as looping.
Here are images to help convey the concepts visually:
- Infographic explaining how to speed up Python data processing scripts using Process Pools:

- Flowchart showing the data processing workflow with Process Pools:
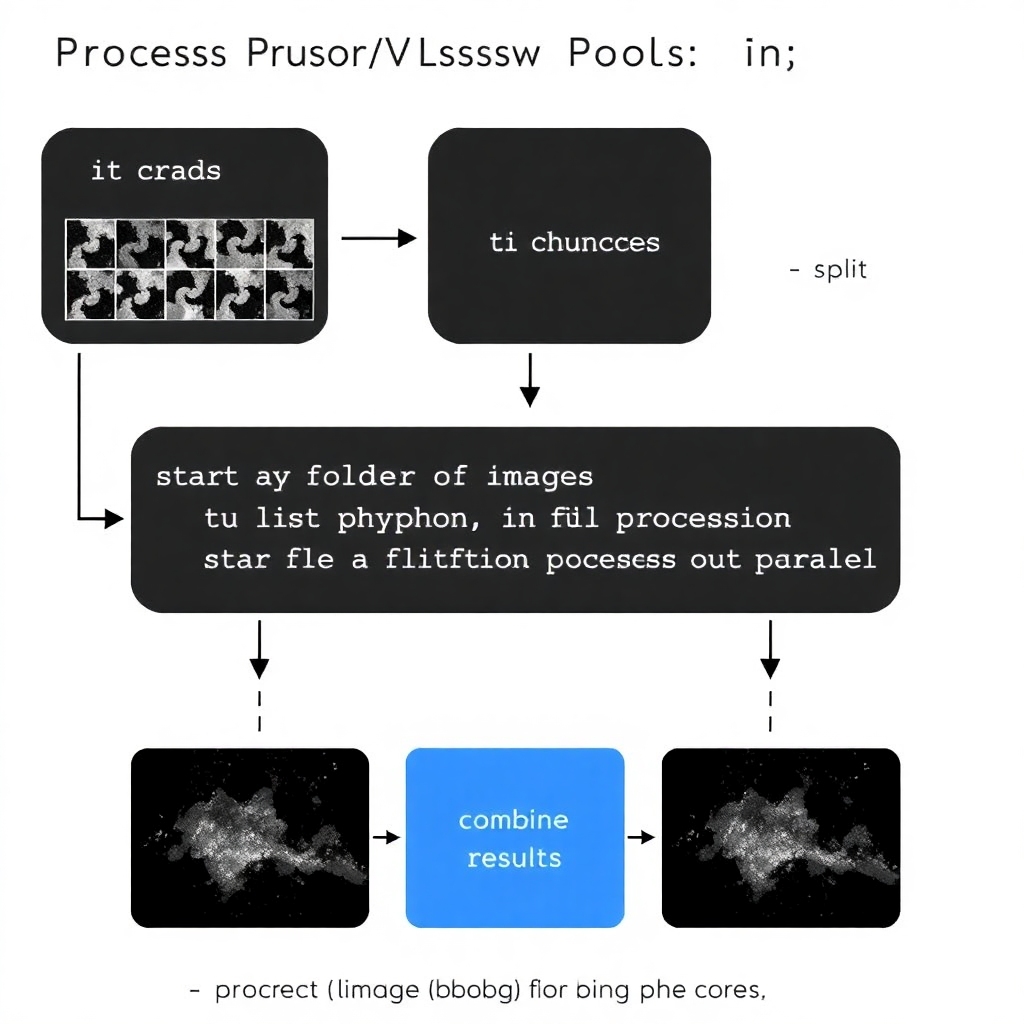
These visuals complement the explanations provided, making the concepts more digestible.