
Introduction
Large language models (LLMs) are incredibly useful for a wide range of applications including question answering, translation, and summarization. Recent advancements have significantly enhanced their capabilities. However, there are instances when LLMs produce factually incorrect responses, especially when the desired answer is not found in the model’s training data. This issue is often referred to as “hallucination.”
To address the hallucination problem, Retrieval-Augmented Generation (RAG) was introduced. This technique allows for retrieving data from a knowledge base that can assist in satisfying the instructions of the user prompt. Although RAG is a powerful tool, hallucinations can still occur. Therefore, it is essential to detect hallucinations and develop mechanisms to alert users or manage these occurrences effectively within RAG systems.
Given that trust in the responses of modern LLM systems is paramount, prioritizing the detection and management of hallucinations is critical.
Understanding RAG Mechanism
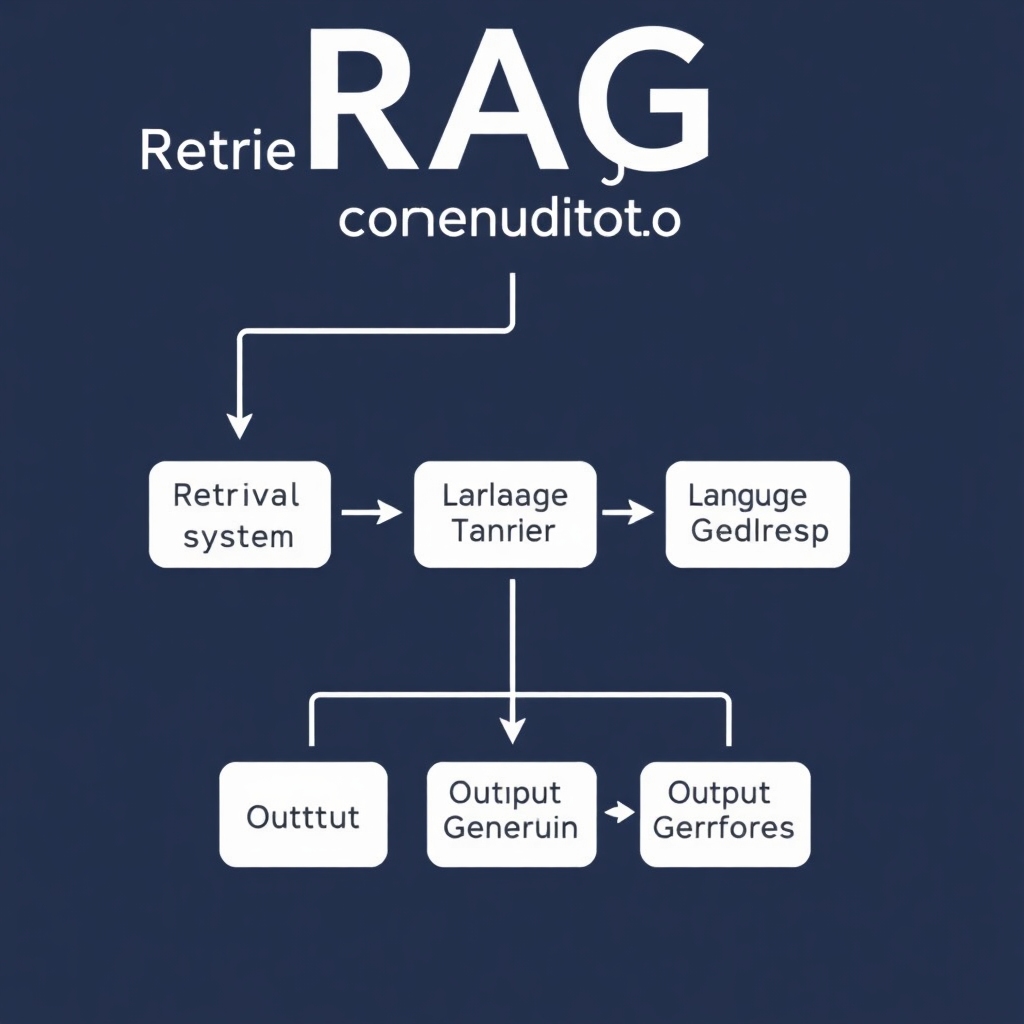
The core functionality of RAG involves retrieving information from a knowledge base through various search methods (sparse or dense retrieval). The most relevant results are integrated with the user prompt and processed to generate the output. Yet, hallucinations may arise due to several factors:
- Incorrect output generation: The LLM might acquire relevant information but may fail to provide correct or coherent responses, particularly when reasoning is required.
- Faulty retrieved information: If the retrieved data is incorrect or irrelevant, the LLM may generate responses that lead to hallucinations.
This discussion will focus specifically on detection methods for hallucinated responses in RAG systems rather than addressing improvements in retrieval processes. We will delve into various techniques for detecting hallucinations to enhance the reliability of RAG systems.
Hallucination Metrics
The first strategy we will explore involves utilizing hallucination metrics from the DeepEval library. These metrics provide a straightforward approach for assessing whether the model generates factual information by utilizing a comparative method, determined by counting the instances of contextual contradictions relative to the total contexts.
Installation and Evaluation Setup
To utilize the DeepEval library, it must first be installed:
pip install deepevalNext, you’ll need to set your OpenAI API key for model evaluation:
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"With the library ready, we can now set up a test to identify hallucinations in the LLM’s output. We will establish the context and configure expected outputs for testing.
context = [
"The Great Wall of China is a series of fortifications made of stone, brick, tamped earth, wood, and other materials, "
"built along an east-to-west line across the northern borders of China."
]
actual_output = ("The Great Wall of China is made entirely of gold and was built in a single year by the Ming Dynasty to store treasures.")Next, we set up the test case alongside the hallucination metric:
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What is the Great Wall of China made of and why was it built?",
actual_output=actual_output,
context=context
)
halu_metric = HallucinationMetric(threshold=0.5)Evaluating Hallucinations
Now, we can execute the test and observe the results.
result = halu_metric.measure(test_case)
print("Hallucination Metric:")
print(" Score: ", halu_metric.score)
print(" Reason: ", halu_metric.reason)Results Interpretation
The output indicates whether hallucinations are present based on a scoring system. A high score suggests significant contradictions between the output and the input context, clearly indicating hallucination occurrences.
Generated Images
- Concept of Hallucination in Language Models

- Visual Representation of the RAG Technique
- Evaluation Techniques for Detecting Hallucinations
- Programmer Coding with DeepEval Library

- Faithfulness Metrics in LLM Outputs

This detailed version of the article, along with the images, provides a clearer understanding of RAG hallucination detection techniques. If you need further revisions or additional information, feel free to ask!