
Unity makes strength. This well-known motto perfectly captures the essence of ensemble methods, one of the most powerful machine learning (ML) approaches—second only to deep neural networks. Ensemble methods effectively tackle complex problems that arise from intricate datasets by combining multiple models to solve a predictive task. This article explores three common strategies to build ensemble models: boosting, bagging, and stacking. Let’s delve into each method.
Bagging
Bagging, short for Bootstrap Aggregating, entails training multiple models independently and in parallel. Typically, these models share the same type, such as decision trees or polynomial regressors. The key difference lies in the fact that each model is trained on a random subset of the training data. After generating predictions, these predictions are aggregated into a singular overall prediction.
- Regression Models: Average the numerical predictions.
- Classification Models: Combine predictions through a majority vote.
This aggregation process minimizes variance and enhances overall performance compared to individual ML models.
Random Data Selection in Bagging:
- Instance-Based Bagging: Models are trained on random subsets of instances sampled with replacement (bootstrapping). This implies a specific instance might be selected none, once, or multiple times.
- Attribute-Based Bagging: Each model employs a different random subset of features, introducing diversity that helps mitigate the “curse of dimensionality.”
The randomness in these selection processes enables the ensemble method to learn effectively while avoiding overfitting, making the system more resilient.

Boosting
Boosting takes a different approach than bagging. Instead of training multiple models in parallel, boosting uses a sequential process where models are trained one after the other. Each subsequent model aims to correct the errors of its predecessor. Over time, as each model addresses the mistakes of the last, the ensemble culminates in a robust solution that is more accurate and adept at identifying complex patterns in the data.
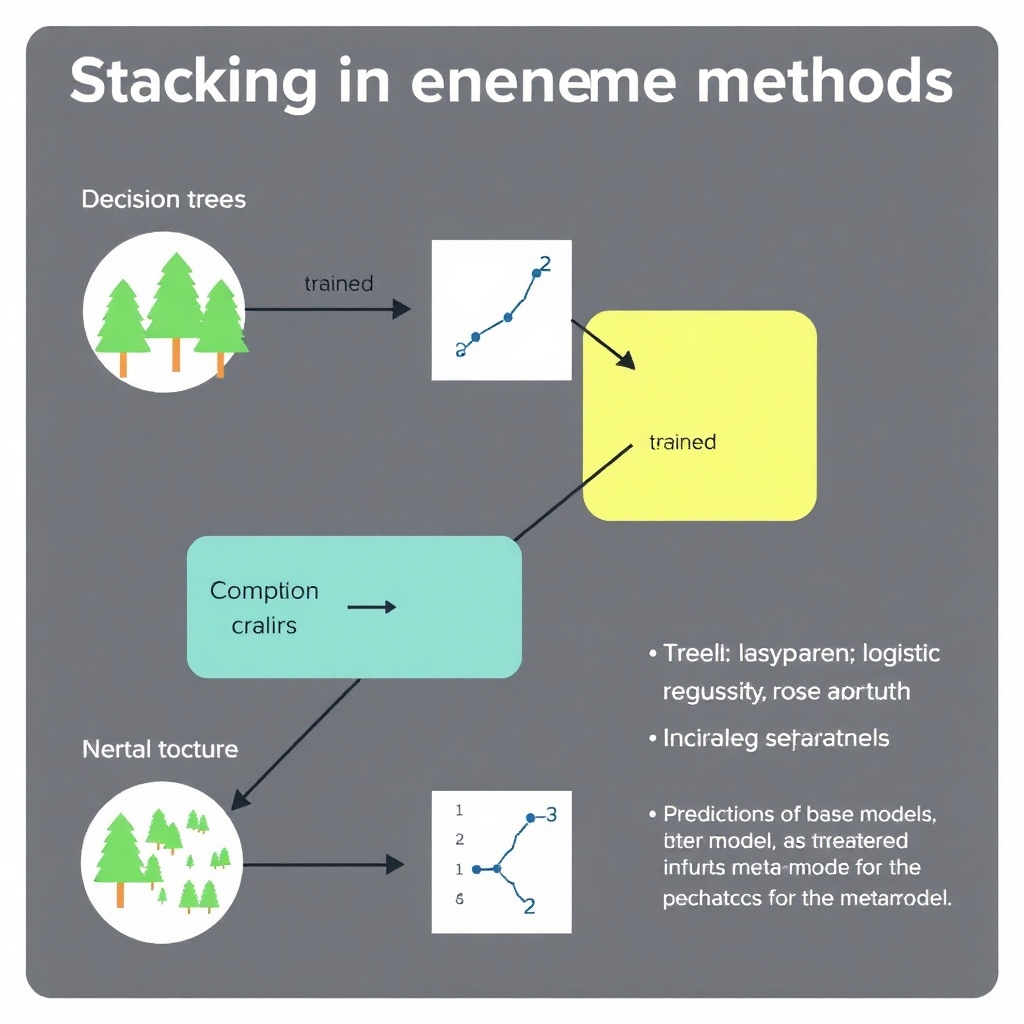
Stacking
Stacking provides a more intricate approach by amalgamating different types of models (such as decision trees, logistic regression, and neural networks), each trained separately on the same dataset. The individual predictions from these various models are not simply aggregated. Instead, they serve as inputs to a final-stage model, referred to as a meta-model, which learns to weigh and combine the predictions as if they were new data instances. This method harnesses the distinct strengths of each model, yielding improved accuracy in the final decision.
Wrapping Up
Ensemble methods like boosting, bagging, and stacking employ the strengths of combining multiple ML models to augment predictive accuracy and robustness. Understanding the unique properties of each approach allows you to tackle complex data challenges more effectively, transforming potential weaknesses of individual models into collective powers.
These images and summary should enhance understanding of ensemble methods and their respective techniques.