
Using LIME to Peek Inside the Black Box
In this series, we delve into programming that enables machines to understand human-written English text. In the first part, we constructed an NLP pipeline aimed at dissecting sentence grammar. In the second part, we identified an easier method: framing our queries as text classification problems. If we can categorize a piece of text accurately, we demonstrate a degree of comprehension of its contents.
For instance, we can analyze restaurant reviews by training a classifier to predict star ratings (from 1 to 5) based solely on the review text:
“Understanding” restaurant reviews by labelling them as “1 star”, “2 stars”, “3 stars”, “4 stars”, or “5 stars.” If the classifier can accurately read any restaurant review and assign the corresponding star rating, it indicates an understanding of English text!
However, the challenge with text classifiers lies in their black-box nature, leaving us unaware of how they arrive at their classifications.
The Need for Model Interpretability
The interpretability of models has long posed a challenge in machine learning. A functioning model without an understanding of its inner workings can be problematic. Fortunately, techniques like LIME (Local Interpretable Model-Agnostic Explanations) allow us to peek inside this black box and comprehend the rationale behind model predictions.
Text Classification as a Shortcut to Understanding Language
In the previous discussion, we built a text classifier capable of interpreting restaurant reviews and predicting user satisfaction. To achieve this, we gathered millions of reviews from Yelp.com and employed Facebook’s fastText to classify each review.
This process seemed almost magical: leveraging extensive data and established algorithms, we devised a classifier that effectively understood English without the intricacies of parsing grammar.
But can we truly trust our model? Just because it functions effectively does not mean it operates with genuine comprehension. Classification models often latch onto data’s simplest characteristics. For instance, reviews from satisfied patrons may be concise, whereas disappointed diners might leave lengthy reviews filled with complaints. This discrepancy raises questions about whether our classifier genuinely understands the text or is merely exploiting review length as a feature.
Understanding Complexity in Machine Learning
In straightforward models, such as linear regression, it’s relatively easy to interpret predictions. For example, consider a model predicting house prices based solely on size. The model simply multiplies the house size by a certain rate, making the logic transparent.
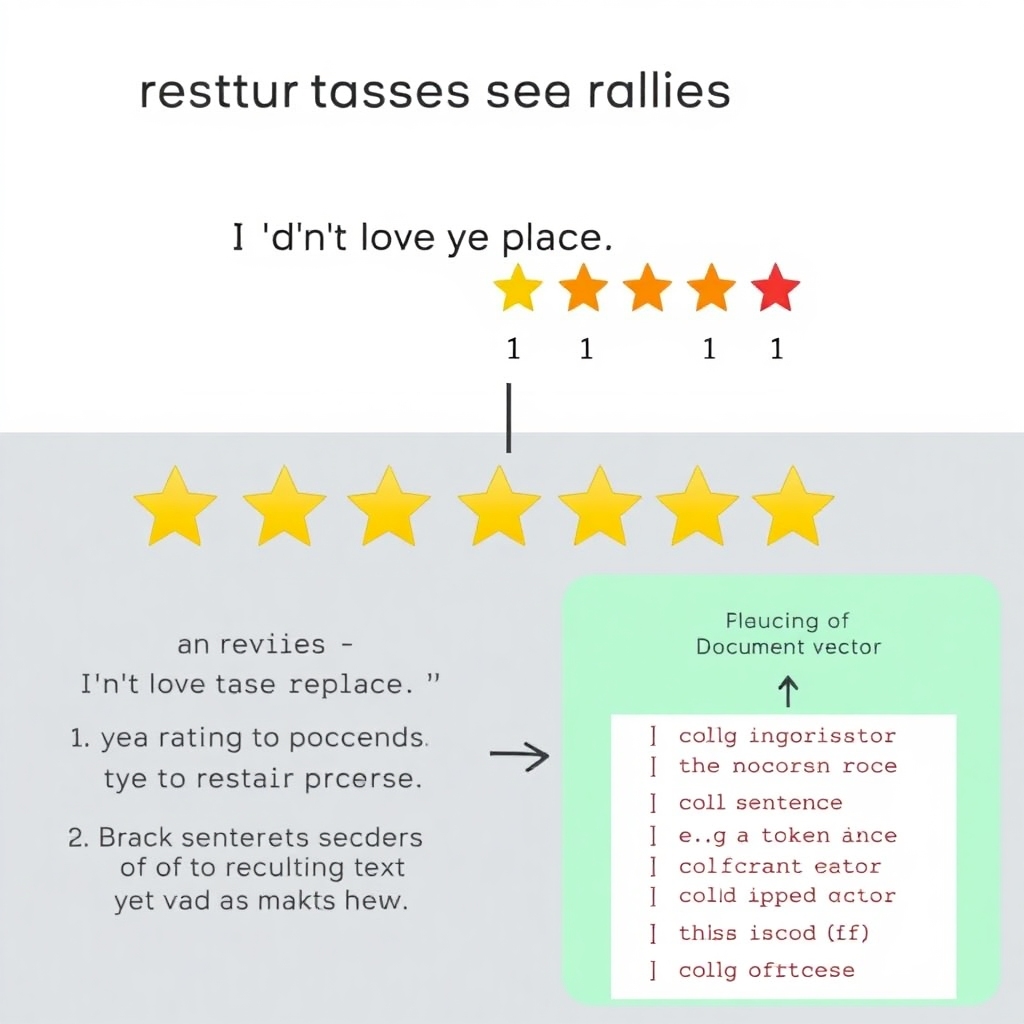
Conversely, understanding predictions from sophisticated models like fastText can be daunting. For instance, consider the phrase “I didn’t love this place :(”. FastText dissects the sentence into tokens and assigns each a numerical representation—essentially encoding its meaning in a complex, high-dimensional space.
Despite the outcome being generated via a linear classifier, it hinges on numerous abstract numbers, complicating human understanding of the model’s reasoning.
Introducing LIME: The Stunt Double for Your Model
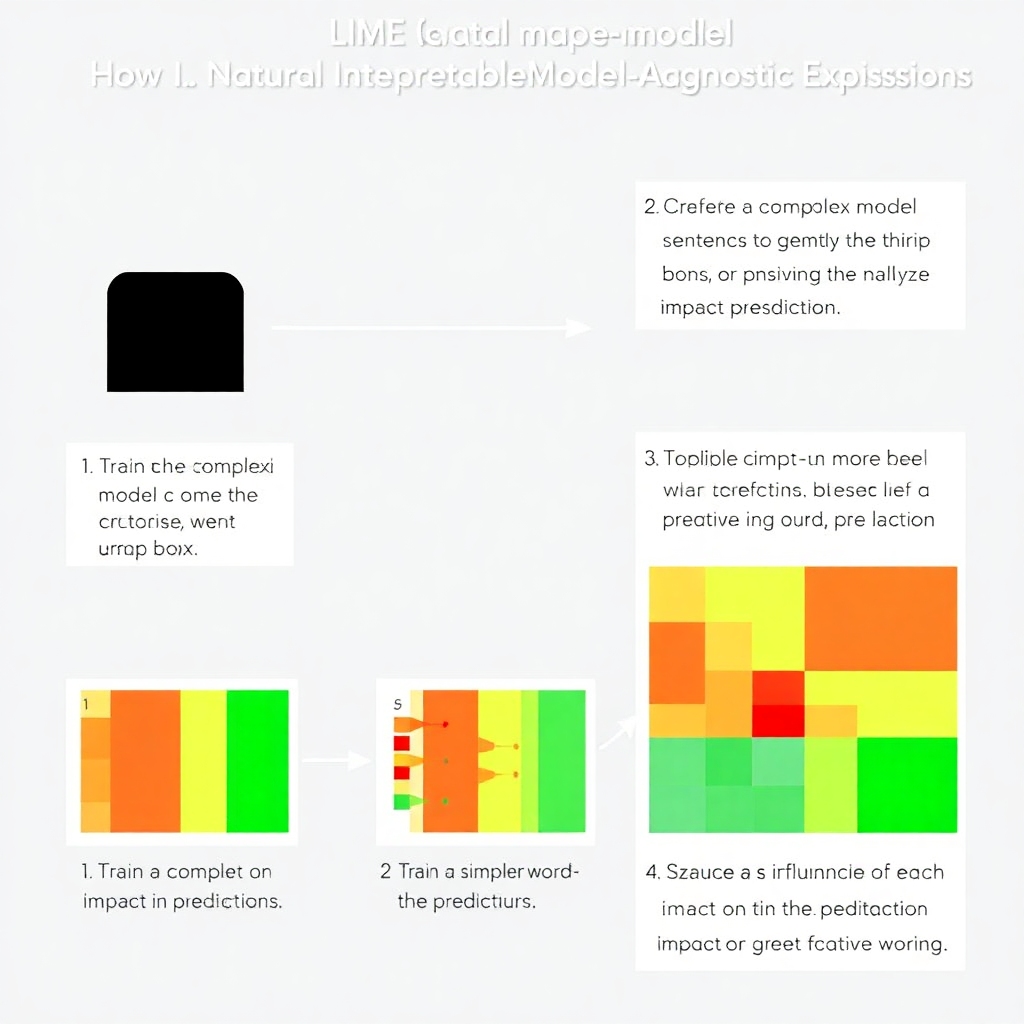
In 2016, researchers introduced LIME, a method for clarifying complex model predictions. The essence lies in training a simpler model that mimics the complex one for a specific prediction. This concept allows us to grasp how the complex model operated in that instance.
To execute LIME, we start by generating variations of a given sentence to observe predictive changes, documenting how the model perceives slight alterations in context.
Using this approach, we can visualize explanations based on word weights in the stand-in model, offering insights into which words influenced the prediction—and thereby bolstering confidence in our model’s accuracy.
Images to Explain Concepts
- Understanding LIME:
- fastText Classifier Example:
This revised article, along with the images, aims to convey the importance of model interpretability in NLP and the utility of LIME in demystifying complex models. If you need any more adjustments or additional content, just let me know!