The World’s Easiest Introduction to Machine Learning
Have you heard people talking about machine learning but have only a fuzzy idea of what it means? Are you tired of nodding your way through conversations with co-workers? Let’s change that!
This guide is designed for anyone curious about machine learning but unsure where to start. Many people have attempted to read technical articles or Wikipedia entries and ended up frustrated, wishing for a straightforward explanation. That’s exactly what this guide aims to provide.
The goal is to make this information accessible to everyone — which means there will be some generalizations. But that’s okay! If this piques anyone’s interest in machine learning (ML), then mission accomplished.
What is Machine Learning?
Machine learning is the concept that generic algorithms can reveal interesting insights about a dataset without the need for custom code tailored to each specific issue. Instead of writing individual code for every problem you face, you simply input data into the algorithm, which then constructs logic based on the given information.
For instance, a classification algorithm can categorize data into different groups. The same algorithm used for recognizing handwritten digits can also classify emails as spam or not, without requiring any changes in the code. It adapts its classification logic based on different training data.
This machine learning algorithm acts like a black box, usable for various classification tasks. “Machine learning” encompasses a broad range of such algorithms.
Two Main Categories of Machine Learning Algorithms
Machine learning algorithms can be broadly categorized into supervised learning and unsupervised learning. Understanding this distinction is crucial.
Supervised Learning
Imagine you are a real estate agent whose business is expanding, and you hire several new trainee agents. You can heuristically estimate a house’s worth, but your trainees lack that experience.
To assist them (and maybe free up time for a vacation!), you decide to create an app that estimates house values based on factors like size and neighborhood, using data from similar property sales.
You gather data for three months, recording details such as number of bedrooms, square footage, neighborhood, and crucially, the selling price. This dataset becomes your “training data.”
Using this information, you seek to develop a program that can predict the price of any given house.

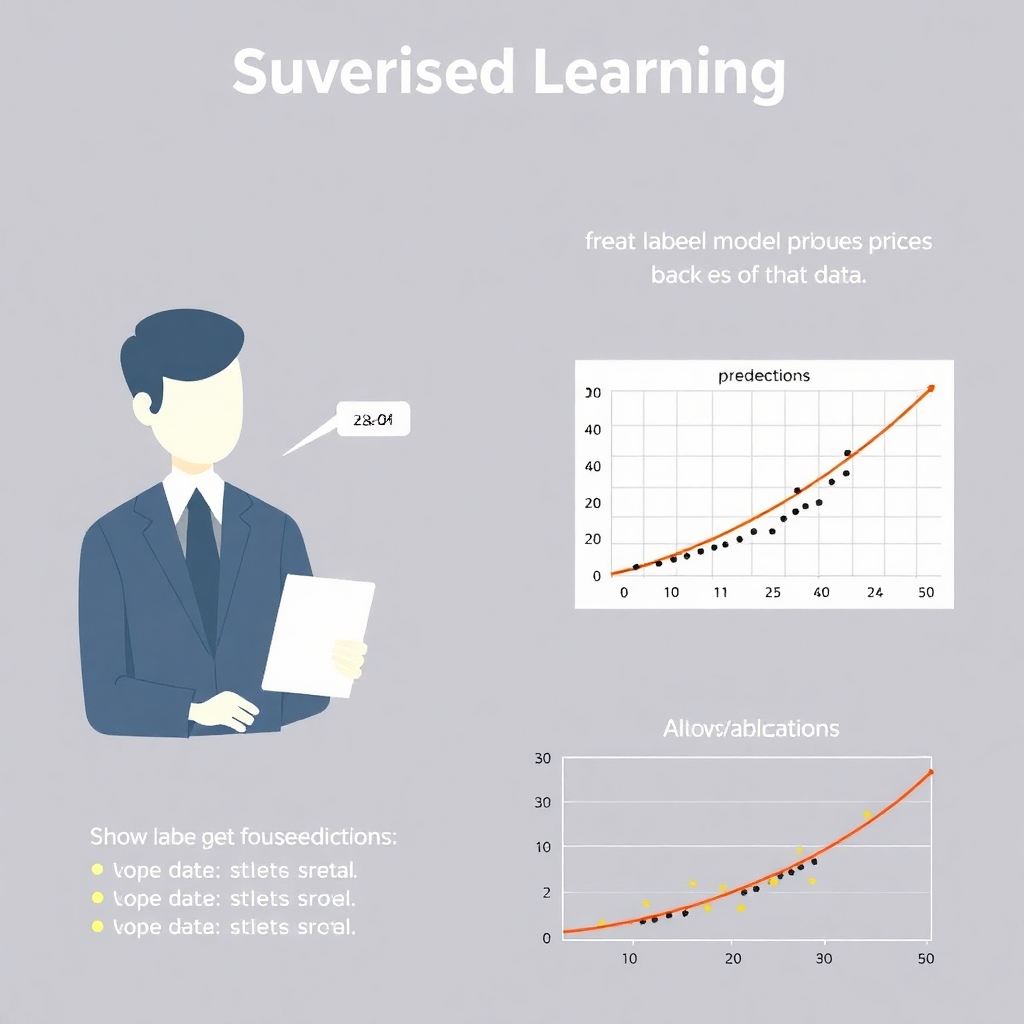
The process involves the algorithm identifying relationships in the training data and forming predictions based on it. You are providing the algorithm with answers in advance, enabling it to deduce the logic needed to estimate house values.
Unsupervised Learning
What if you did not know the selling prices for each house? You can still glean useful insights from the data without any label on sales price, a method known as unsupervised learning.
Picture being given a list of numbers without explanation, tasked with discerning patterns or groupings. This approach could reveal market segments indicating buyer preferences, helping to tailor marketing strategies.
Unsupervised learning allows you to uncover relationships without relying on labeled data. You could determine outliers — unusual properties that differ from the norm — and target specific buyer segments, boosting your sales strategy.

While this article will concentrate on supervised learning, it’s important to note that unsupervised learning is equally intriguing and vital as data labeling becomes less necessary.
Does Estimating House Prices Count as “Learning”?
Unlike humans who can tackle various scenarios intuitively, current machine learning models excel only in specific tasks. A more precise definition of “learning” in this context could be about establishing an equation to solve a particular issue based on example data.
The term “machine learning” reflects this idea, although a more accurate description would be cumbersome. In 50 years, if we’ve made breakthroughs into artificial general intelligence (AGI), the notions discussed here may seem antiquated.
Writing the Program
To create the house price estimation program, consider this potential initial structure:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
price_per_sqft = 200 # Average cost per sqft
...
return priceWhile you could craft rules, they wouldn’t be perfect or easily adaptable as prices fluctuate. Instead, the goal is for the computer to deduce the function automatically, refining its predictions by discovering the right weight to assign to various factors influencing price.
The journey to find optimal weights can be performed through iterations and adjustments—this repeatedly refines your function until it predicts accurately across various houses.
Mind-Blowing Insights
Your use of data, along with a few simple steps, leads to a robust function that estimates house values. This approach often surpasses traditional methods that people might use for problematic tasks.
Ultimately, machine learning doesn’t comprehend terms like “square footage”, yet the algorithm effectively predicts desired outputs based on numerical inputs, demonstrating its power.
Conclusion
Machine learning may seem magical at times; however, it is essential to remember that it is based on statistical relationships present in the input data. If a human expert can’t derive a solution with the available data, neither can a computer.
The landscape of machine learning is evolving, with resources becoming increasingly accessible. Organizations like Coursera offer excellent courses that can guide you in your journey to delve deeper into this intriguing field.
Feel free to reach out if you need anything else or additional images to further elaborate on specific points!