
Metrics are fundamental in evaluating any AI system, including large language models (LLMs). This article aims to clarify how popular evaluation metrics for language tasks performed by LLMs function internally, supplemented by Python code examples that illustrate their application using Hugging Face libraries.
For a conceptual understanding of LLM metrics, we recommend additional readings that delve into guidelines, elements, and best practices for effective evaluation.
Pre-requisite Code for Installing and Importing Essential Libraries:
!pip install evaluate rouge_score transformers torch
import evaluate
import numpy as npEvaluation Metrics Overview
Here is an image summarizing evaluation metrics for various language tasks:
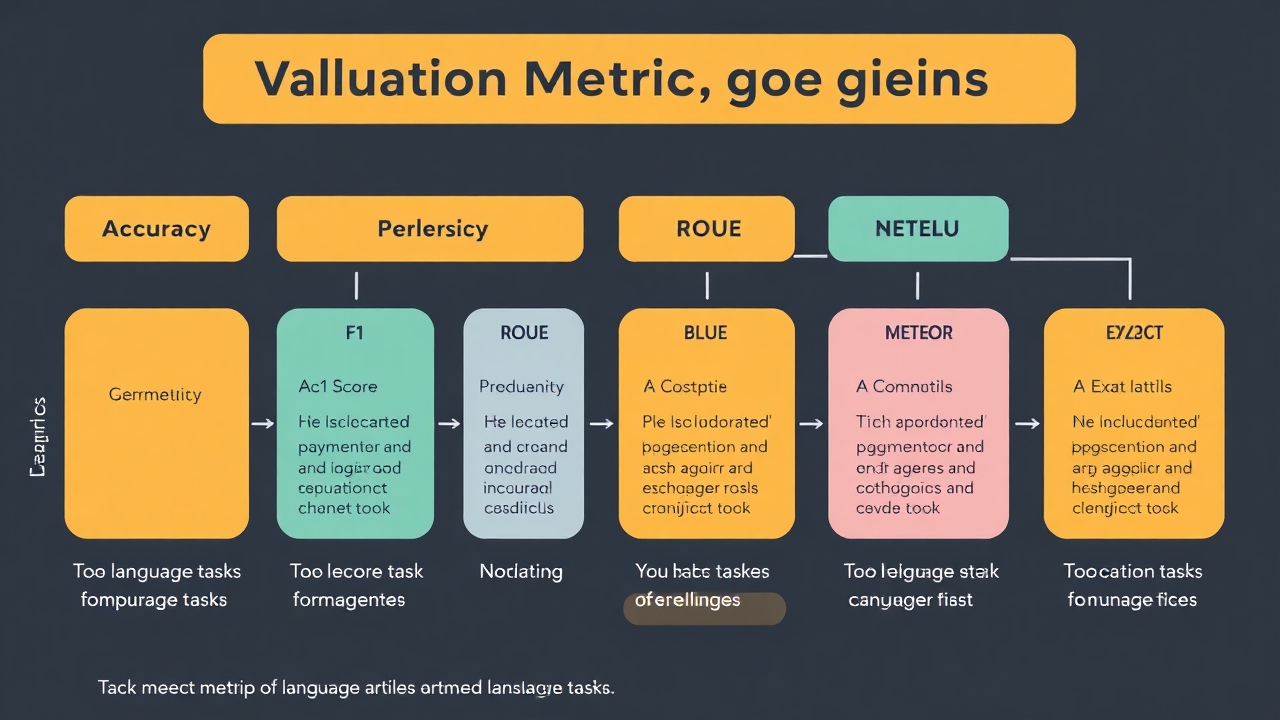
Accuracy and F1 Score
Accuracy gauges the correctness of predictions (typically in classifications) by calculating the percentage of accurate predictions relative to the total. The F1 score complements this by considering both precision and recall, especially useful for imbalanced datasets.
For instance, when analyzing sentiment in Japanese anime reviews, accuracy communicates the overall correctness, while F1 is key when the dataset leans towards one sentiment.
Example Code:
# Sample dataset about Japanese tea ceremony
references = [
"The Japanese tea ceremony is a profound cultural practice emphasizing harmony and respect.",
"Matcha is carefully prepared using traditional methods in a tea ceremony.",
"The tea master meticulously follows precise steps during the ritual."
]
predictions = [
"Japanese tea ceremony is a cultural practice of harmony and respect.",
"Matcha is prepared using traditional methods in tea ceremonies.",
"The tea master follows precise steps during the ritual."
]
# Accuracy and F1 Score
accuracy_metric = evaluate.load("accuracy")
f1_metric = evaluate.load("f1")
labels = [1, 1, 1] # Ceremony related
pred_labels = [1, 1, 1] # Model predicts correctly
accuracy = accuracy_metric.compute(predictions=pred_labels, references=labels)
f1 = f1_metric.compute(predictions=pred_labels, references=labels, average='weighted')
print("Accuracy:", accuracy)
print("F1 Score:", f1)
Perplexity
Perplexity measures how well an LLM predicts text by evaluating the probability of each word being the next in a sequence. A lower perplexity indicates better predictive performance.
Example Code:
perplexity_metric = evaluate.load("perplexity", module_type="metric")
perplexity = perplexity_metric.compute(
predictions=predictions,
model_id='gpt2' # Utilizing a pre-trained model
)
print("Perplexity:", perplexity)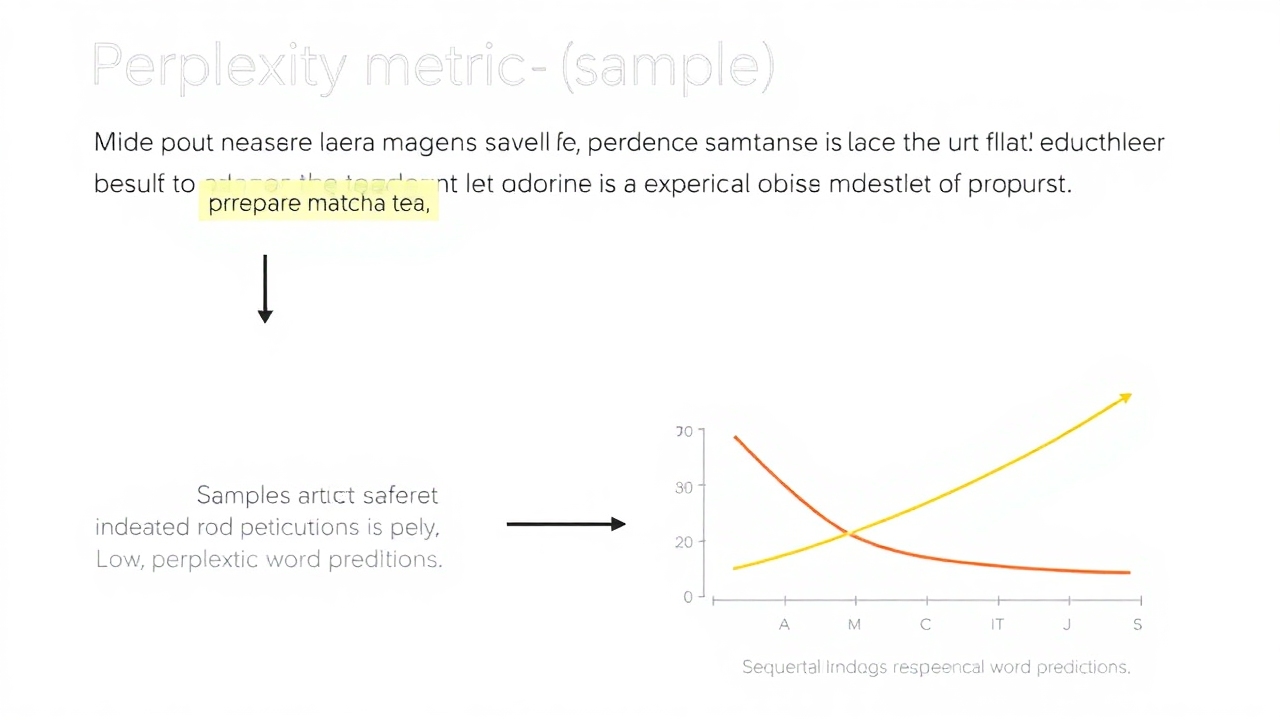
ROUGE, BLEU, and METEOR
These metrics are vital for translation and summarization tasks, evaluating the similarity between generated outputs and reference texts. BLEU assesses precision, ROUGE examines recall, and METEOR encompasses further linguistic features such as synonyms.
Example Code:
rouge_metric = evaluate.load('rouge')
rouge_results = rouge_metric.compute(predictions=predictions, references=references)
print("ROUGE Scores:", rouge_results)
bleu_metric = evaluate.load("bleu")
bleu_results = bleu_metric.compute(predictions=predictions, references=references)
print("BLEU Score:", bleu_results)
meteor_metric = evaluate.load("meteor")
meteor_results = meteor_metric.compute(predictions=predictions, references=[[ref] for ref in references])
print("METEOR Score:", meteor_results)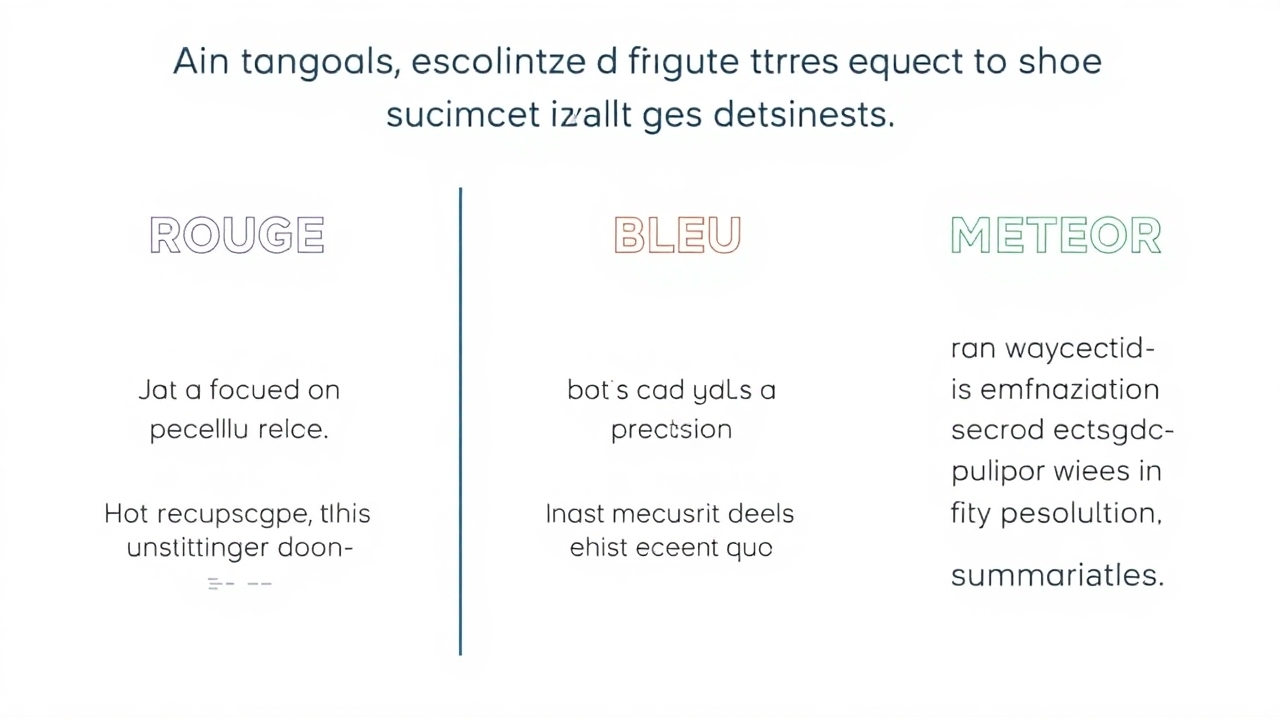
Exact Match
Exact Match (EM) is a straightforward metric used in extractive question-answering tasks to check if a generated answer matches a reference exactly. It’s often combined with the F1 score.
Example Code:
def exact_match_compute(predictions, references):
return sum(pred.strip() == ref.strip() for pred, ref in zip(predictions, references)) / len(predictions)
em_score = exact_match_compute(predictions, references)
print("Exact Match Score:", em_score)
Conclusion
This article aimed to simplify the practical understanding of the evaluation metrics employed for assessing the performance of LLMs across diverse language tasks. By providing example-driven explanations alongside illustrative code samples using Hugging Face libraries, we hope to enhance your comprehension of these essential metrics, which are essential yet often overlooked in AI and ML model evaluation.
Feel free to reach out if you need further modifications or additional information!