
Computers excel at managing structured data, like what’s found in spreadsheets and databases. However, humans often communicate in natural language, primarily through words, which presents a challenge for computers.
In our world, much information exists in unstructured forms, such as raw text in various human languages. This raises a compelling question: how can we enable computers to comprehend and extract data from this unstructured text?
Enter Natural Language Processing (NLP) – a branch of artificial intelligence dedicated to allowing computers to process and understand human languages. In this article, we’ll explore the intricacies of NLP and how Python can be utilized to write programs that extract information from raw text.
Can Computers Understand Language?
Since the advent of computers, programmers have sought to develop systems capable of understanding languages like English, which is invaluable given the vast amount of text produced throughout human history. While computers cannot fully grasp languages in the same way humans do, they can perform remarkable tasks using NLP techniques.
Recent advancements in NLP are easily accessed via open-source Python libraries such as spaCy, Textacy, and neuralcoref, allowing developers to leverage powerful tools with minimal code.
The Challenges of Extracting Meaning from Text
Parsing and comprehending human language involves complex challenges. Natural languages like English often defy logical structures and consistent rules, illustrated by ambiguous sentences, such as:
“Environmental regulators grill business owner over illegal coal fires.”
This could mean regulators are questioning a business owner about illegal coal burning, or it could be taken literally, leading to an entirely different interpretation.
To tackle these complexities, NLP typically employs a systematic approach known as a pipeline. This method breaks down the understanding of language into manageable segments, where machine learning techniques solve smaller problems individually.
Building an NLP Pipeline: A Step-by-Step Approach
Let’s consider the following sentence derived from Wikipedia:
“London is the capital and most populous city of England and the United Kingdom.”
This sentence carries several key details, and the goal is to teach a computer to recognize information such as the identity and significance of ‘London.’
Step 1: Sentence Segmentation
Break the text into individual sentences for easier processing.
Step 2: Word Tokenization
Separate each sentence into individual words, known as tokens.
Step 3: Predicting Parts of Speech
Assign parts of speech (noun, verb, etc.) to each token, which aids in understanding the context.
Step 4: Text Lemmatization
Reduce words to their base forms to establish their central meaning.
Step 5: Identifying Stop Words
Filter out common filler words (e.g., “and,” “the”) that may introduce noise in analysis.
Step 6: Dependency Parsing
Understanding the grammatical structure and relationships between words in the sentence.
Step 7: Named Entity Recognition (NER)
Detect and categorize proper nouns representing real entities (places, people, organizations).
Step 8: Coreference Resolution
Resolve pronouns to their corresponding nouns, improving context understanding.
With this pipeline, significant insights and facts can be extracted from text efficiently.
Images to Illustrate the Concepts
- NLP Illustration
Here is an image of an illustration depicting Natural Language Processing, showcasing a computer with graphs and text analysis, including elements like sentence segmentation, tokenization, and named entity recognition in a flowchart style:
- NLP Pipeline Visualization
Here is an image of a visual representation of the NLP pipeline, showing steps from raw text to named entity recognition: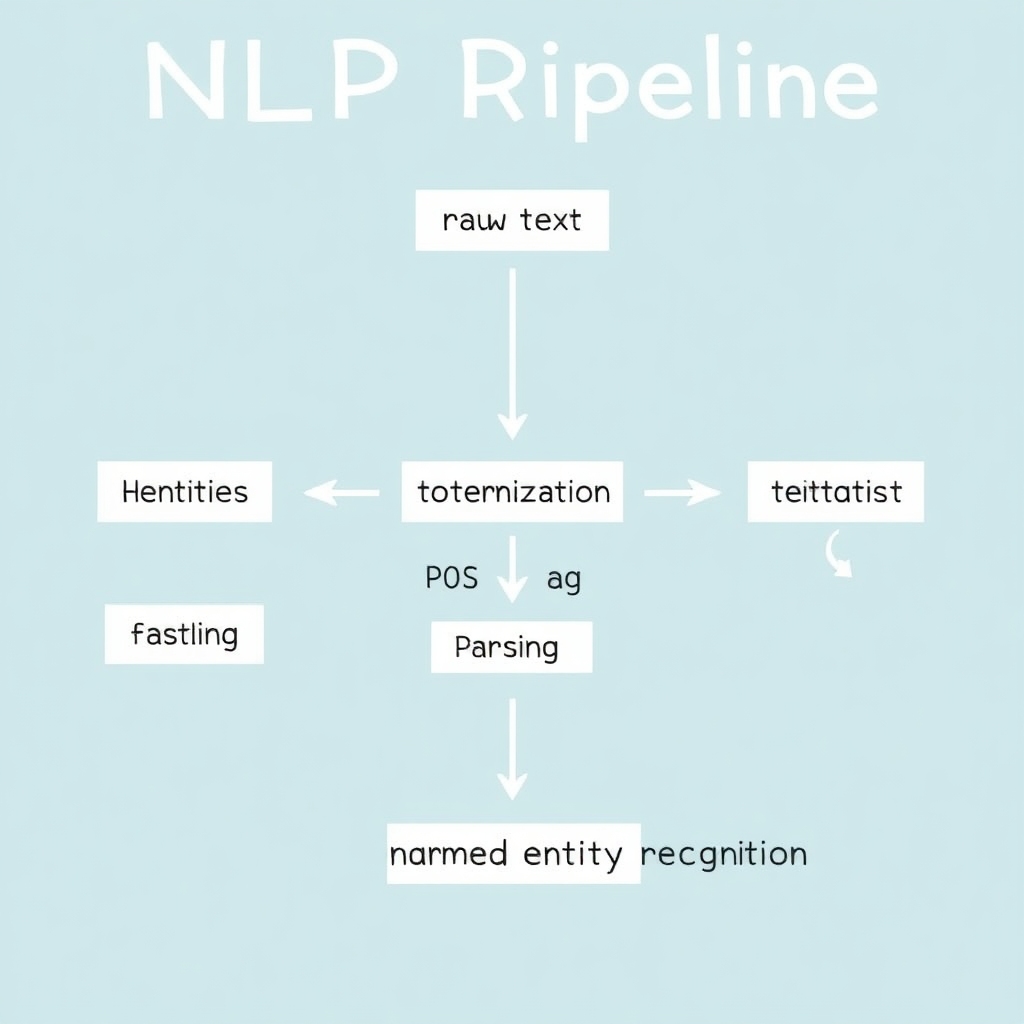
- Challenges in NLP
Here is an image of an infographic highlighting the challenges in Natural Language Processing, with examples of ambiguity and complexities in language:
These resources provide a comprehensive overview and visual aids to better understand the fascinating realm of Natural Language Processing!