
From the inception of programming, hackers have found ways to exploit software vulnerabilities. While malicious hackers might manipulate program errors to steal data and cause chaos, what about systems powered by advanced deep learning algorithms? Surely, they are invulnerable? Surprisingly, even the most sophisticated neural networks can be easily deceived.
Neural Networks vs. Hacking
Before launching a new system with deep neural networks, it’s vital to understand how attackers can compromise them. For instance, let’s visualize a scenario where we operate an auction website, like eBay, aiming to prevent the sale of prohibited items such as live animals.
Instead of employing numerous reviewers to oversee millions of transactions, we could utilize deep learning to automatically assess auction images, flagging any that violate policies.
To design this, we would train a deep convolutional neural network (CNN) to distinguish between acceptable and prohibited items, using a dataset that includes thousands of images.
The process involves feeding the CNN training images, validating predictions, and fine-tuning the model through a back-propagation algorithm until it can reliably classify inputs.
However, there are caveats…
Limitations of Convolutional Neural Networks
CNNs are celebrated for their prowess in recognizing intricate patterns in images. Common logic suggests that minor adjustments in an image should yield negligible changes in predictions. However, research has revealed a disturbing reality: certain pixel alterations can significantly mislead neural networks, producing erroneous outputs without drastically altering the image’s appearance.
To illustrate, hackers could manipulate a picture of a prohibited item so that the CNN misclassifies it.
How Does This Work?
The neural network classifier divides the input into distinct categories. By subtly nudging data points, one can force a misclassification. In imaging with deep learning, every classification represents thousands of pixels, providing ample opportunities for manipulation—if done covertly, this can effectively fool the system.
Process of Manipulation
- Input the original image.
- Check the neural network’s prediction against the desired outcome.
- Adjust the image pixels using back-propagation.
- Repeat until the desired classification is achieved without apparent distortion.
This process is referred to as generating an adversarial example.
Example of Adversarial Manipulation
Here is an artistic representation illustrating this concept:

Diagram of Creating Adversarial Examples
A diagram illustrating the process is as follows:

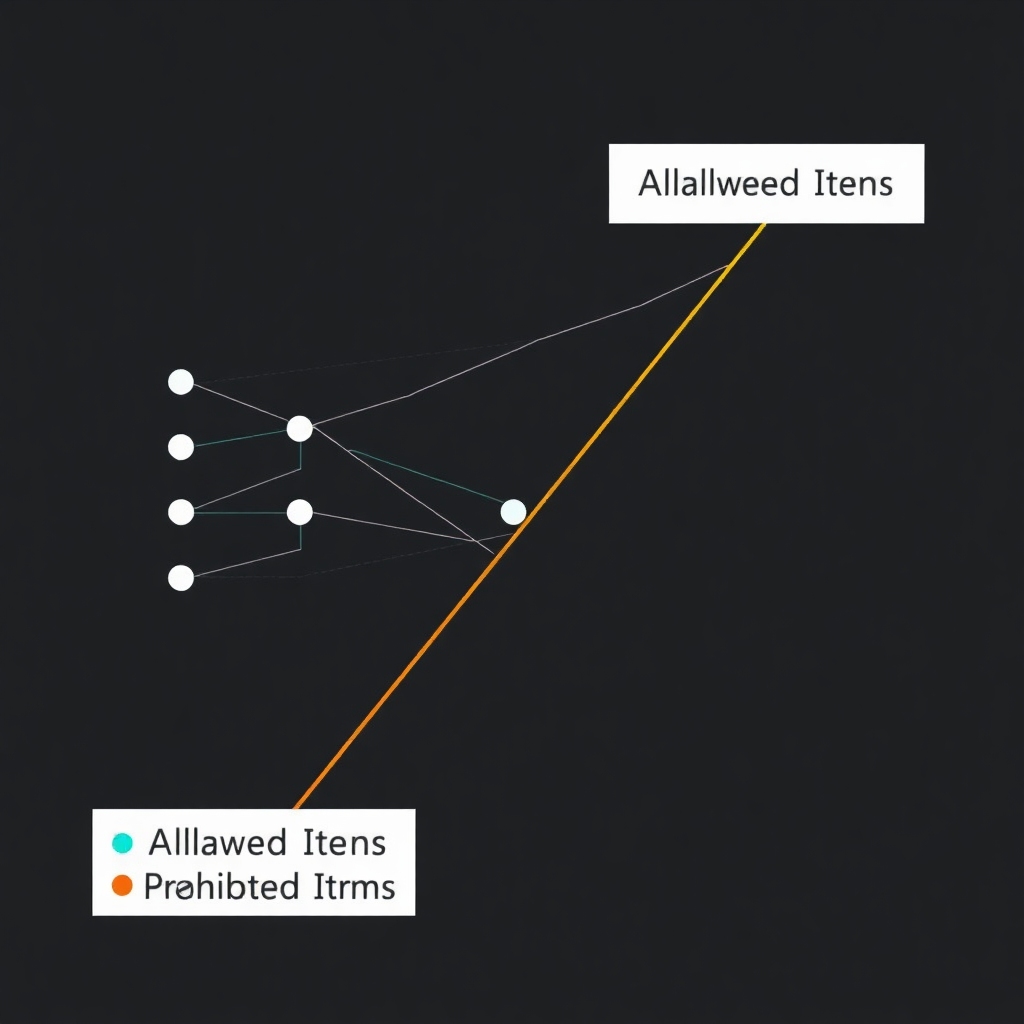
Graphical Representation of a Neural Network
This graphical representation demonstrates how a neural network classifies images and establishes a boundary:
Fun Representation of Hacking
Here’s a humorous cartoon depiction of a hacker’s manipulation of an image to deceive a neural network:

Implications and Defense Measures
Creating hacked images might be engaging as an academic exercise, but it poses real threats in practical applications, such as manipulating self-driving vehicles or bypassing content filters.
To protect against such attacks, researchers advocate for adversarial training—this involves including hacked images in training datasets to bolster resilience against future manipulations.
The quest for effective defenses continues, suggesting that future innovations will need to remain adaptive to these emerging threats.
Feel free to let me know if you need further modifications or additional images!